AI Infrastructure
llmxy
LLM token distribution and intelligent routing solution. Unify access to multiple large language model providers, balance token usage, and route every request to the best-fit model automatically.
llmxy sits in front of your LLM providers as a unified gateway. It distributes tokens across accounts and keys, routes each request to the most suitable model based on cost, latency, and capability, and gives you full visibility into how your AI workloads consume resources.
- Intelligent Routing. Route requests to the optimal model and provider based on prompt characteristics, cost, latency, and availability.
- Token Distribution. Pool and distribute tokens across multiple keys and accounts with quota controls, rate limiting, and automatic failover.
- Multi-Provider Support. One unified API in front of OpenAI, Anthropic, and other major LLM providers — switch or mix without changing your application code.
- Usage Analytics. Track token consumption, cost, and latency per model, key, and tenant with real-time dashboards.
- Secure by Design. Centralized key management, request auditing, and policy enforcement keep your AI traffic compliant and safe.
Built for modern cloud-native environments, llmxy is lightweight, horizontally scalable, and easy to deploy. Stop managing keys, quotas, and provider quirks by hand — let llmxy handle the plumbing so your team can focus on building great AI products.
Product Screenshots
The llmxy interface combines a self-service user console with an admin workspace for routing, monitoring, and billing operations.
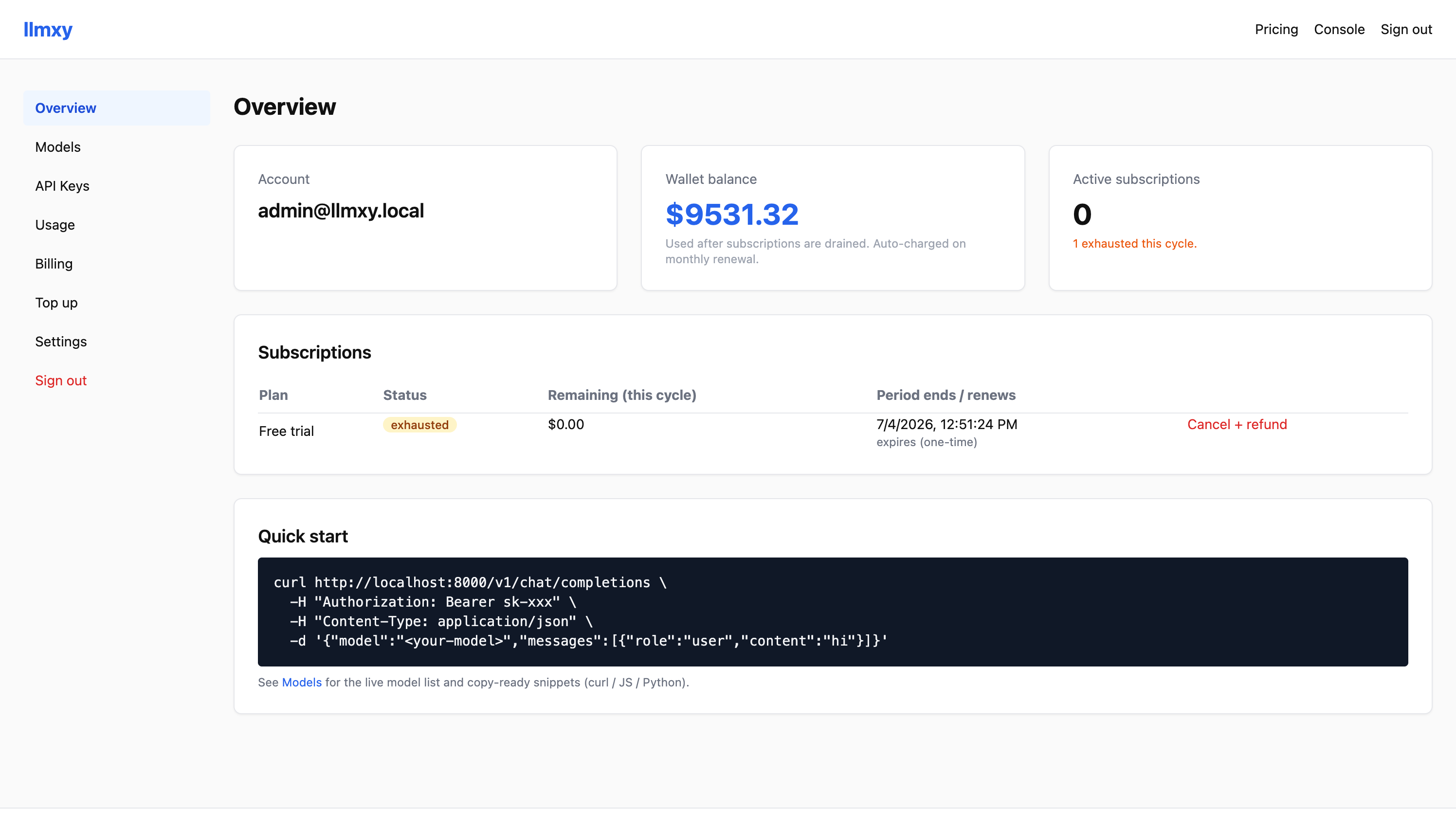
User overview
Account balance, subscriptions, and quick-start API examples give users a clear path from signup to first request.
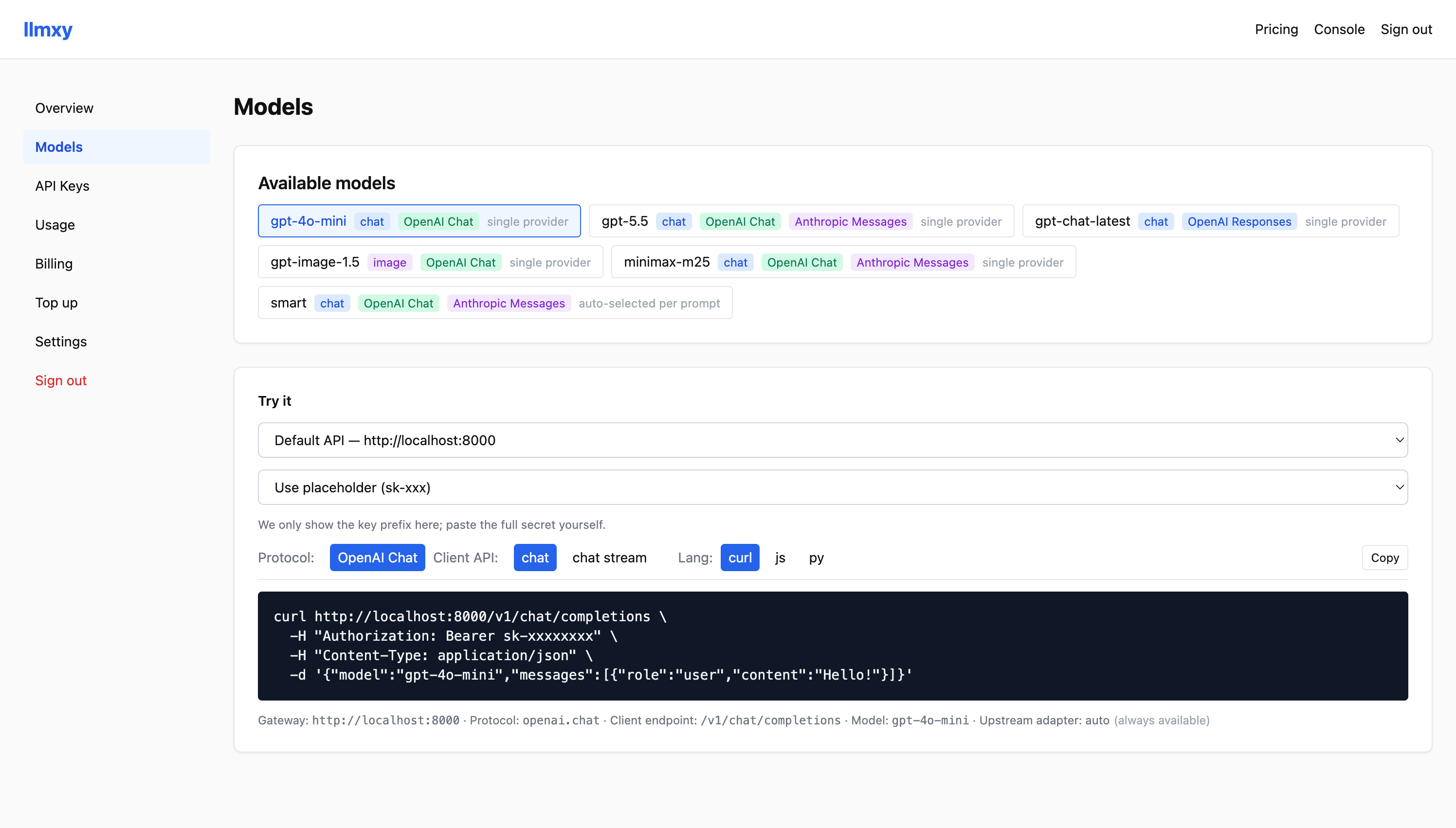
Models and API snippets
Expose available models with protocol tags and copy-ready curl, JavaScript, and Python request examples.
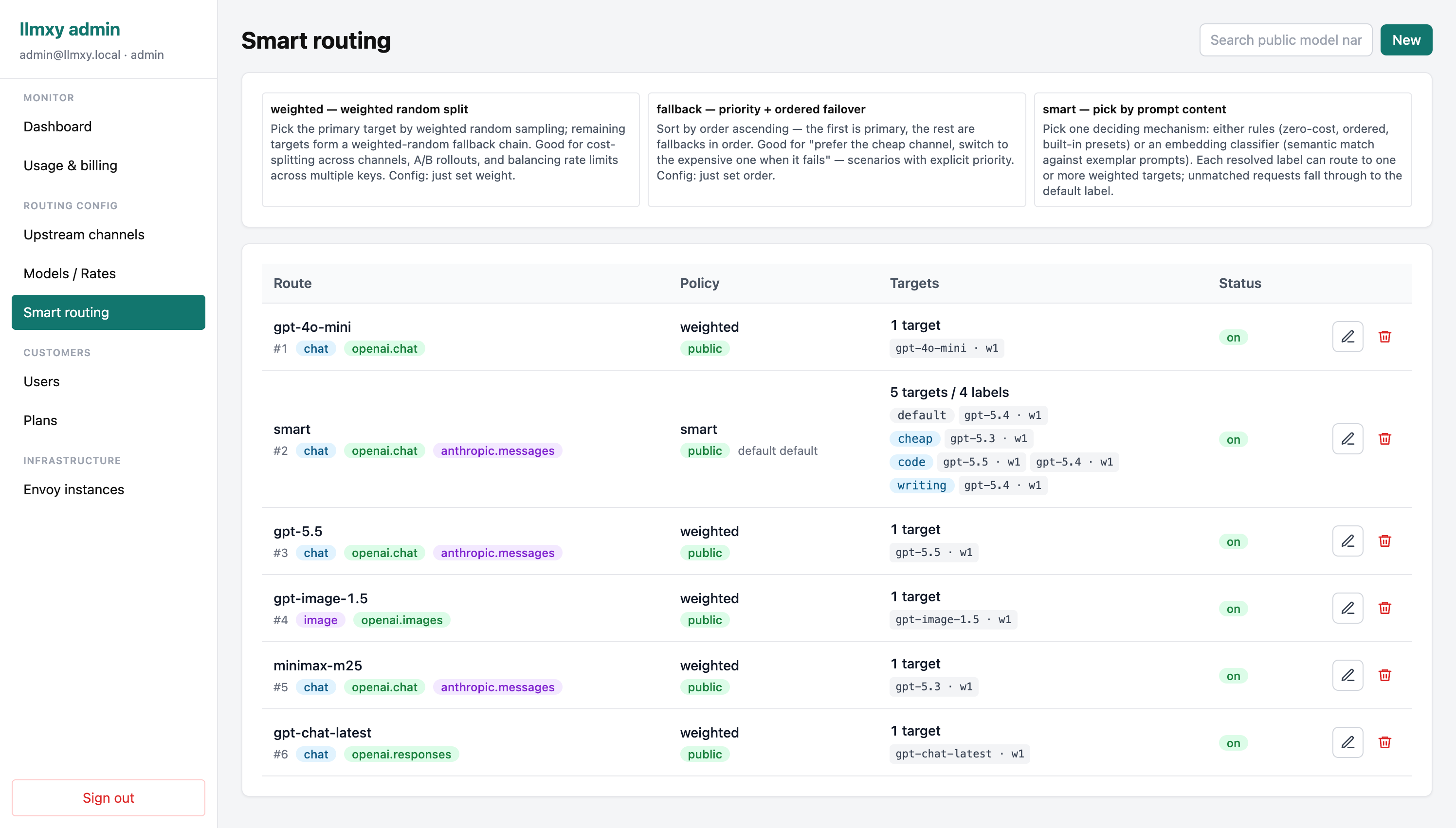
Smart routing rules
Configure weighted, fallback, and prompt-aware routes across upstream providers from the admin console.
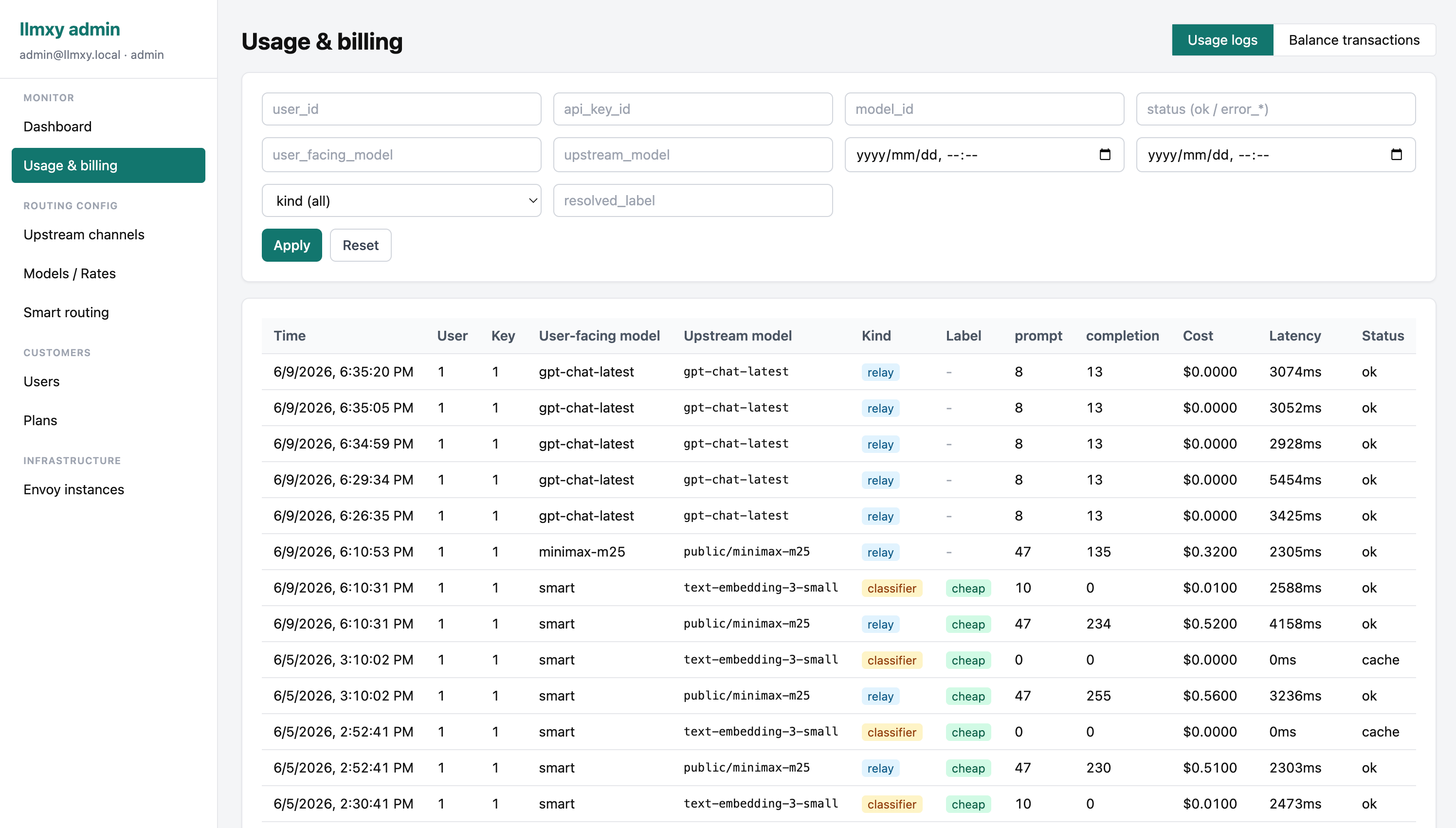
Usage and billing logs
Filter usage by user, key, model, status, and label while tracking cost, latency, and token consumption.
Open Source & Enterprise Ready
llmxy is open source and community driven. Use the community edition to get started in minutes, or talk to us about enterprise deployments with advanced security, multi-tenant isolation, and dedicated support.